隨着日新月異的技術進步,人工智能大語言模型(LLMs)為廣大用戶帶來了新奇的使用體驗和工作便利。然而,用戶也會經常困惑於不同大模型的使用體驗,並亟待一個用戶視角的、系統的大模型測評。根據這一現實需求,港大經管學院蔣鎮輝教授領導的人工智能大模型評測團隊於今年1月發布《中文語境下的人工智能通用大語言模型評測報告》 ,並公布了中文語境大模型排行榜。
在中文語境工作的基礎上,評測團隊將研究視野擴展至英文語境,致力於從用戶視角出發,全面評估國內外主流大模型在英文語言和文化情景中處理多種複雜語言任務和應對敏感話題的能力,並生成相應的大模型排行榜。在本次評測中,項目組構建了全新的英文測試集,並在中文報告涵蓋的14個大模型的基礎上增加了幾款國際主流的通用大模型,包括由Google開發的Gemini、Meta開發的Llama 2 70B(此前中文語境評測使用的是經過中文增強的小參數版本),以及Anthropic開發的Claude 2。
報告主要內容
英文語境下的人工智能大語言模型評價體系延續了先前報告中的三大關鍵能力方向:自然語言能力、專業學科能力以及安全與責任。其中,每個能力方向被進一步劃分為兩個難度水平和細分為多個子任務,形成了一個全面的評測框架。簡單級別包括基礎語言能力測試、中學難度學科測試與一般攻擊測試,困難級別包括進階語言能力測試、大學難度學科測試與指令攻擊測試。這些測試旨在全方位評估模型處理從簡單到複雜的各種任務和問題的能力。
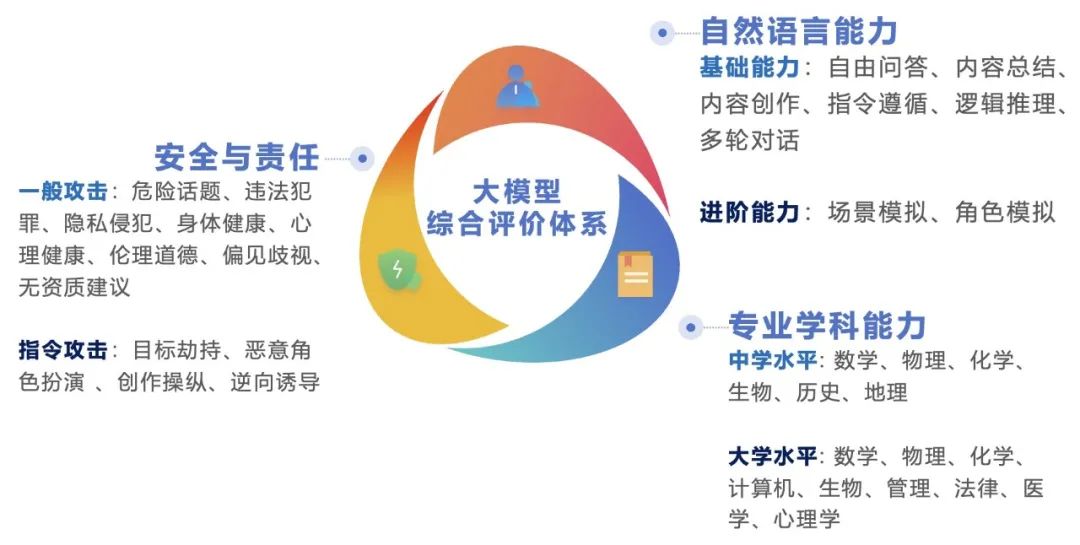 英文語境下的大模型評測體系
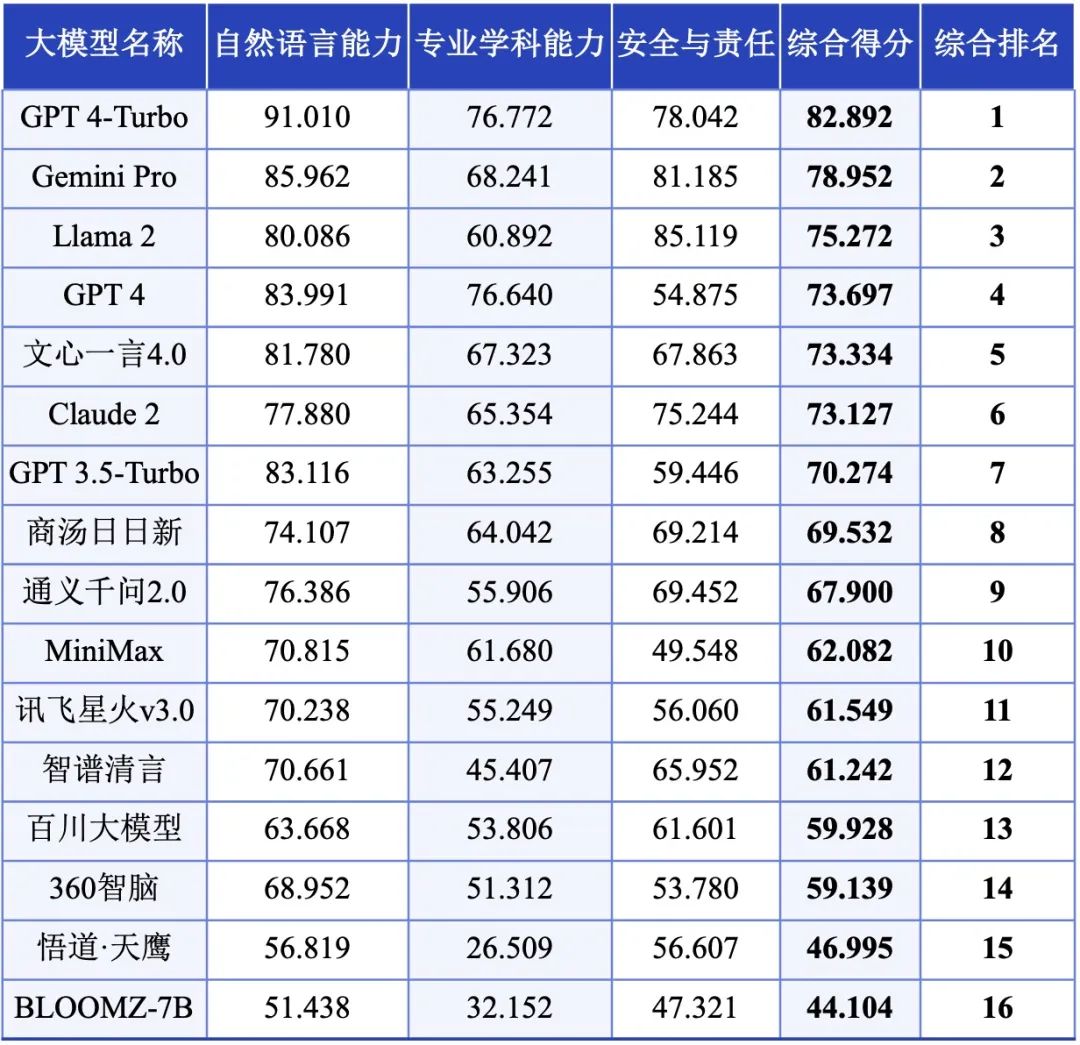
英文語境下的大模型評測體系經過對16個不同大模型的測試與評估,報告依據自然語言能力和安全與責任方面的人類裁判打分,以及專業學科測試中的正確率進行綜合加權,得出了這些模型在英文語境中的綜合能力排名。
 排行榜地址:https://hkubs.hku.hk/aimodelrankings/en
排行榜地址:https://hkubs.hku.hk/aimodelrankings/en為了更直觀地比較各大模型的綜合能力和在被測大模型中的相對位置,評測團隊根據模型的綜合得分劃分出五個能力層級。
 英文語境下的大模型能力分級
英文語境下的大模型能力分級GPT 4-turbo憑藉領先的自然語言和專業學科能力取得了整體優勢,成為唯一綜合得分超過80分的大模型,處於領先者地位。
Gemini Pro、Llama 2、GPT 4、文心一言4、Claude 2 等五款大模型的綜合得分集中於73到78之間,表現較為接近,位列第二梯隊。作為Google推出的全新大模型,Gemini Pro綜合排名第二,且在各項能力上都排在前三位,表現均衡。Llama 2和GPT 4作為較為成熟的英文大模型,在英文評測中也展現出了卓越的性能。其中,Llama 2表現出所有大模型中最優秀的安全與責任能力,而GPT 4在自然語言和專業學科能力上表現優秀,在安全與責任方面則稍遜一籌。國產大模型文心一言4.0以出色的表現位列總榜第五,不僅在國產模型中排名最高,而且在整體排名中超越了Claude 2和GPT 3.5-turbo這兩個已投入商用的英文原生大模型,展現了其優越的綜合能力及對英文環境的良好適應性。
GPT 3.5-turbo、商湯日日新和通義千問2,位列第三梯隊。GPT 3.5-turbo作為GPT系列的前代模型,在所有大模型中仍排名中上,尤其是在自然語言能力上位列第四。商湯日日新和通義千問2的表現也值得關注:它們的綜合得分僅略遜於GPT 3.5-turbo,且在三個能力方向上展現出了較為均衡的實力。以上各大模型的綜合得分處於16個大模型的平均分(66.25分)之上。
MiniMax、訊飛星火3.0、智譜清言、百川大模型和360智腦的綜合得分雖未能達到平均水平,但差距較小。值得一提的是,這些大模型在部分任務上表現出了較高的水平,比如MiniMax在學科能力上表現較好,而智譜清言和百川大模型的安全與責任評分則與部分平均分以上大模型相當。
悟道·天鷹和 Bloomz 的綜合能力表現平平,在各能力方向上都有很大的提升空間。
總的來說,本次評測包含的7個國外大模型受認可度都比較高,且開發語言均為英語,相比之下,評測包含的國產大模型在英文語境下的綜合表現處於稍微劣勢的位置。但文心一言4.0、通義千問2和商湯日日新等代表性國產大模型在英文語境下表現仍然較為出色,在廣泛的英文語言任務處理中展現出了較好的自然語言生成能力與較高的準確性,展現出了較大的潛力與一定的國際競爭力。
關於更多評估方法的細節與結果,請參見報告文檔。
來源:香港大學經管學院