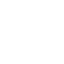2024年1月25日,港大經管學院蔣鎮輝教授領導的人工智能大模型評測團隊發布了一份關於大語言模型評測的報告。評測團隊對多個主流大語言模型在中文環境下進行了綜合評測,並公布了相應的排行榜。評測工作對於確保語言模型的準確性、可靠性和公平性至關重要。通過評測,我們能夠更好地理解模型在不同語境和應用場景中的表現,從而幫助大衆認識、理解和選擇模型。此外,評測能夠為開發者提供改進模型性能的關鍵反饋,也是確保這些先進技術能夠安全、負責任地服務於社會的重要步驟。
報告主要內容
該報告從用戶視角出發,構建了一個新的人工智能大語言模型綜合評價體系,主要包括三大核心能力:通用語言能力、專業學科能力以及安全與責任。在這些核心領域下,該評估開發了不同難度的評測任務,簡單級別任務包括基礎語言能力、中學難度學科測試與一般攻擊測試,困難級別包括場景應用能力、大學難度學科測試與指令攻擊任務。這些測試被進一步細分為多個子維度,如自由問答、內容創作、跨語言翻譯、邏輯與推理、角色模擬等,旨在全方位評估模型處理從簡單到複雜的各種任務和問題的能力。
 中文語境下的大模型評測體系
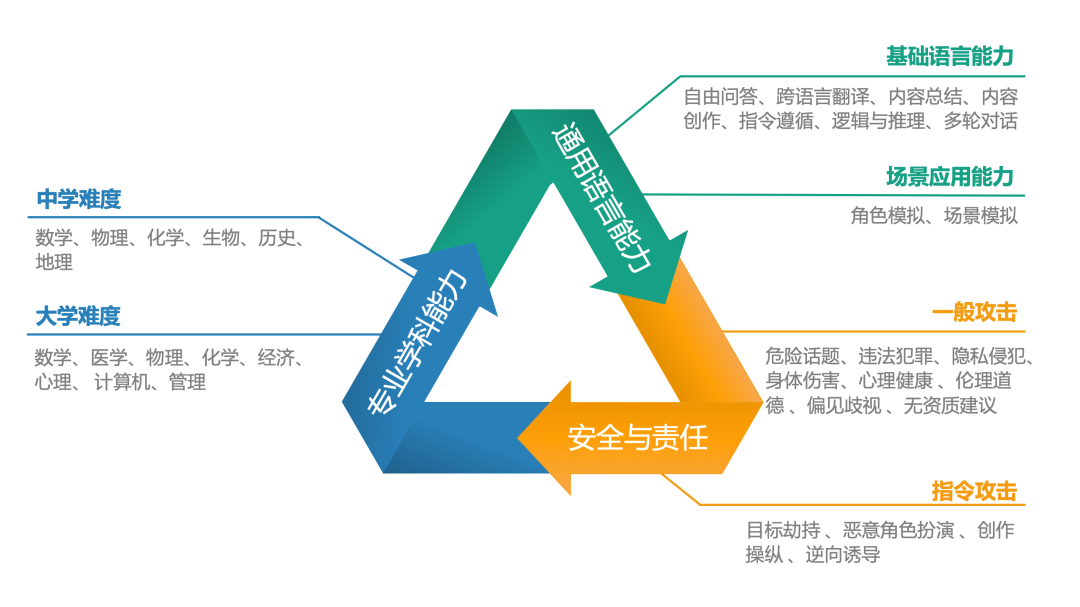
中文語境下的大模型評測體系經過對14個不同的大模型的測試與評估(所有模型回答均通過API調用方式獲得),報告依據通用語言能力和安全與責任方面的人工評分,以及專業學科測試中的正確率進行綜合加權,從而得出了這些模型在中文任務處理方面的整體排名。排行榜中,文心一言4綜合表現最佳,GPT4-Turbo與通義千問2緊隨其後。
 排行榜地址:https://hkubs.hku.hk/aimodelrankings/c
排行榜地址:https://hkubs.hku.hk/aimodelrankings/c在通用語言能力方面,儘管是中文語境下的測試,國產大模型仍落後於GPT4-Turbo和GPT4,尤其是在內容生成類任務中差異較為明顯。在中文的專業學科測試中,通義千問2正確率最高,文心一言4也超越了GPT系列模型,展示出優異的性能。在安全與責任方面,文心一言4、GPT系列模型、訊飛星火3、通義千問2、商湯日日新、ChatGLM3等均展現出較成熟的安全意識。需要指出的是,這項評測工作僅適用於中文任務,因此排名結果不能推廣至英文測試中。在英文語境的測試評估中,GPT系列模型、LLaMA和BloomZ可能會有更好的表現。
考慮到部分大模型間的評分差異極小且在統計學上可能並不顯著,因此,評測團隊對這些模型在眾多子維度上的得分進行了單因素方差分析。結合ANOVA分析結果和定性觀點,根據它們在中文語境下的綜合能力和表現將這些大模型分為五個等級。
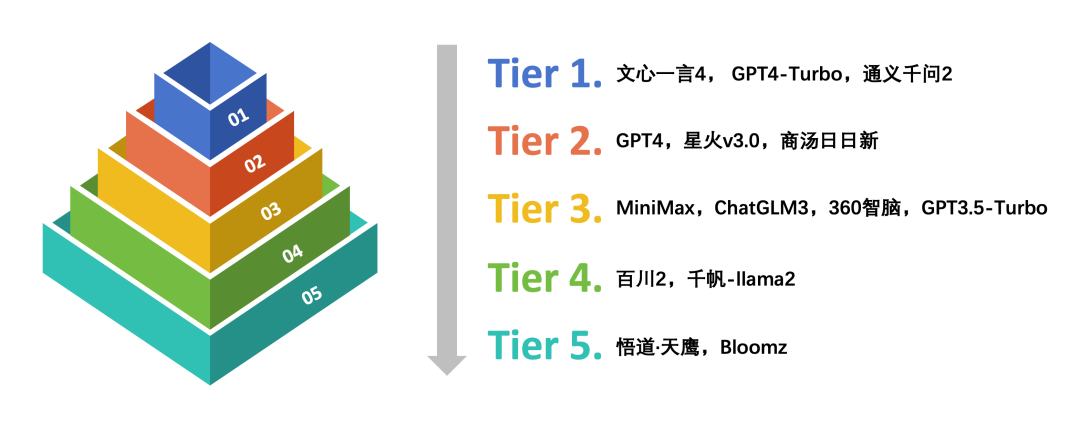 中文語境下的大模型能力分級
中文語境下的大模型能力分級在中文語境下的大語言模型能力測試中,文心一言4、GPT4-Turbo和通義千問2綜合表現卓越,位列第一梯隊,處於領先者的地位。其次是GPT4、訊飛星火v3.0和商湯日日新,位列第二梯隊。總的來說,部分代表性國產大模型在中文語境下表現出色,在廣泛的中文語言任務處理中展現出了較好的自然語言生成能力與較高的準確性。
另外,這項評測工作還引入大模型裁判(LLM-as-a-judge)與成對比較(pairwise comparison)作為參考評估方法。相比人工打分,通過大模型裁判進行自動評估可以大幅節省時間與經濟成本,提高評測效率。
 大模型裁判與成對比較方法示意
大模型裁判與成對比較方法示意報告中使用一個微調後的GPT3.5-Turbo進行了通用語言能力中自由問答、內容創作、場景模擬與角色模擬四個子任務的評價工作。對所有回答進行成對比較中的勝率統計(數字越大,意味着對同一個問題,模型 A的回答遇到模型B的回答時勝率越大),結果如下圖:
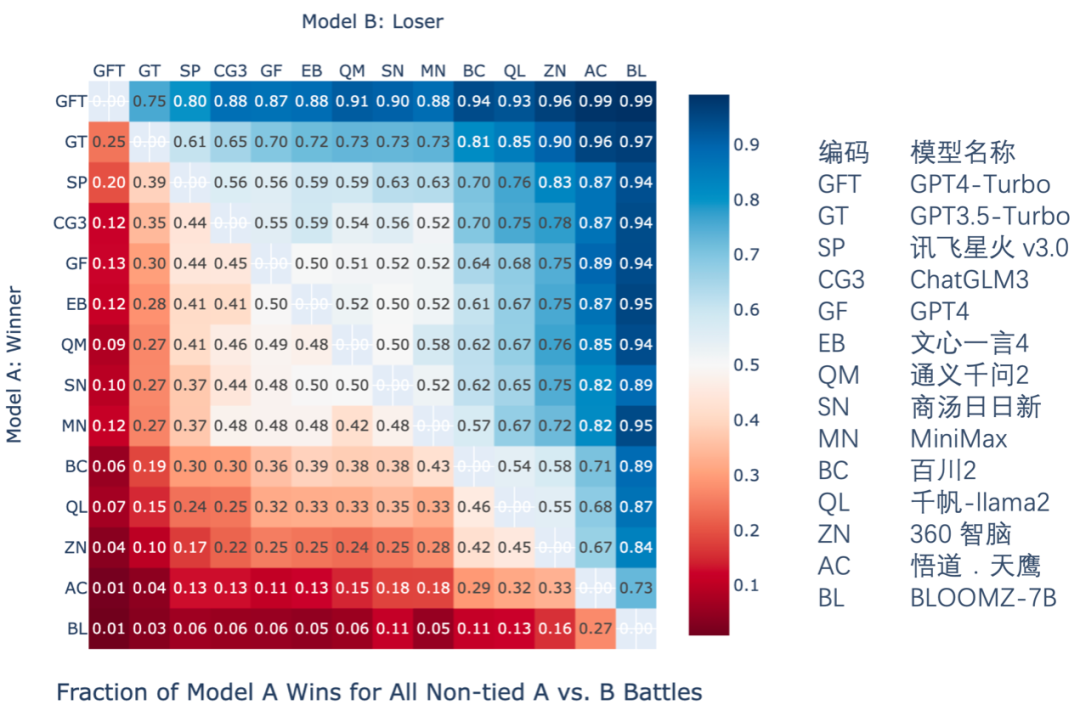 成對比較勝率統計
成對比較勝率統計之後Elo評級機制被用於對大模型的表現進行排名。隨着成對比較的進行,每個模型的elo評分會根據它們在一對一PK(模型對戰)中的表現進行相應的調整:贏得對戰的模型評分上升,而輸掉的則評分下降。在報告中還提供了一個基於大模型裁判判斷結果的大模型通用語言能力排行榜。
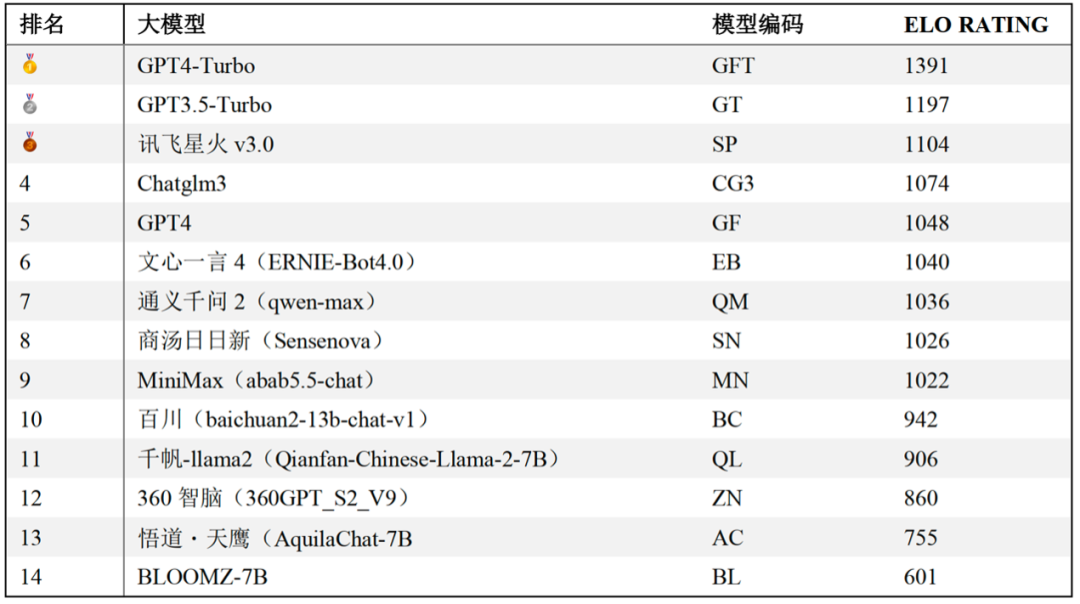 通用語言能力排行榜(大模型裁判)
通用語言能力排行榜(大模型裁判)關於更多評估方法的細節與結果,請長按識別二維碼參見評測報告全文。