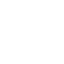首頁 > 正文
中國信通院醫療健康大模型效能評估結果出爐 訊飛星火醫療大模型四大能力排名第一
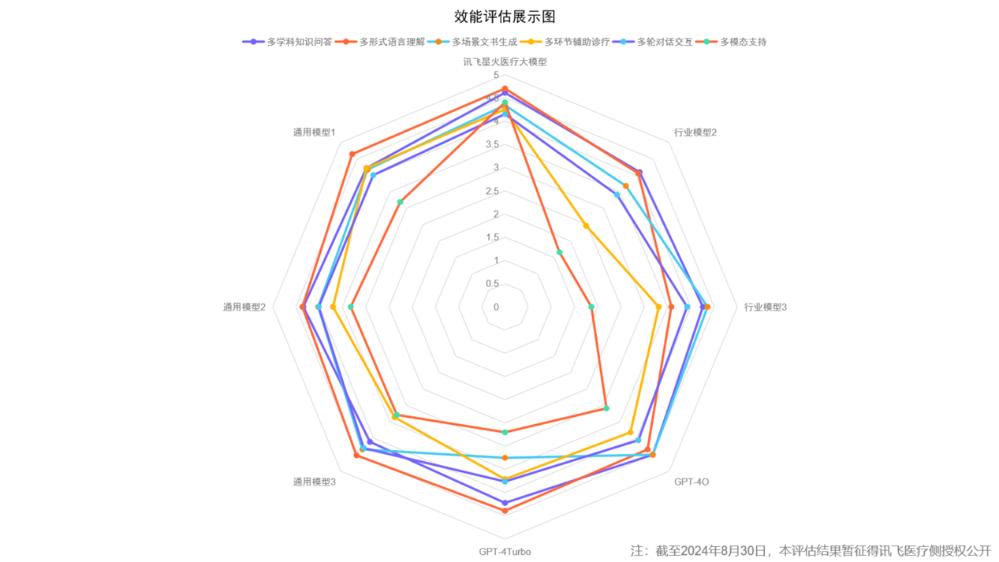
近期,中國信通院對包括GPT-4Turbo、GPT-4O等國際通用大模型,文心一言、通義千問、混元和智譜清言ChatGLM等國內通用大模型,以及靈醫Bot、誇克健康助手、訊飛星火醫療大模型和華佗GPT II等醫療健康行業大模型進行了效能評估。通過構建測試數據集、開展符合性驗證和模擬實際應用場景,邀請醫療健康、人工智能領域十餘位專家形成評估小組,對參測大模型的多輪問詢結果進行準確性、完整性、流暢性、可解釋性等維度的綜合評分,考察大模型在多學科知識問答、多形式語言理解、多場景文書生成、多環節輔助診療、多輪對話交互、多模態支持等六大方向的實際應用效能。
結果顯示,通用大模型在醫學知識廣度方面具有一定優勢,醫療健康行業大模型在特定醫療任務上表現優異。其中,訊飛星火醫療大模型能力超越GPT-4Turbo、GPT-4O等國內外大模型,多學科知識問答、多形式語言理解、多環節輔助診療、多模態支持等技術能力排名第一。具體而言,在個人畫像、健康干預方案、病歷文書生成及質控、檢驗檢查報告解讀、體檢報告單解讀、藥盒解讀等細分任務中,訊飛星火醫療大模型表現均處於領先;在健康常識、疾病百科、用藥知識、電子病歷結構化、專業知識生活化、考試輔助智能化、導醫導診便民化、輔助首診及推薦檢驗檢查、輔助確診、用藥安全指導等方向上,訊飛星火醫療大模型展現了高度專業性。
近年來,中國醫療人工智能行業的市場規模顯著增長。根據弗若斯特沙利文的資料,中國醫療人工智能行業的市場規模由2019年的27億元增至2023年的88億元,複合年增長率為33。8%,且預計到2033年將達到3157億元,2023年至2033年的複合年增長率為43.1%。
而訊飛醫療已在中國醫療人工智能行業取得競爭優勢。據公開資料顯示,訊飛醫療主要經營四大塊業務,分別是面向基層的醫療和疾病管理;面向醫院的醫院管理和診療輔助;面向患者的診斷、治療服務;以及面向區域的公共衛生管理。根據弗若斯特沙利文的資料,訊飛醫療2023年的收入規模在中國醫療人工智能行業中排名第一,市場份額為5.9%。此外,其智醫助理是全球首個且是唯一一個通過國家執業醫師資格考試(綜合筆試)的智能解決方案,2023年在中國基層醫療機構CDSS市場中排名第一,市場份額占61.5%。
https://res.youuu.com/zjres/2024/10/17/Z4kbU0wMKzV0dDcmcuao7coQpKlFAKNTJ7g.png
掃描二維碼分享到手機
+關註