


 今日熱搜
今日熱搜



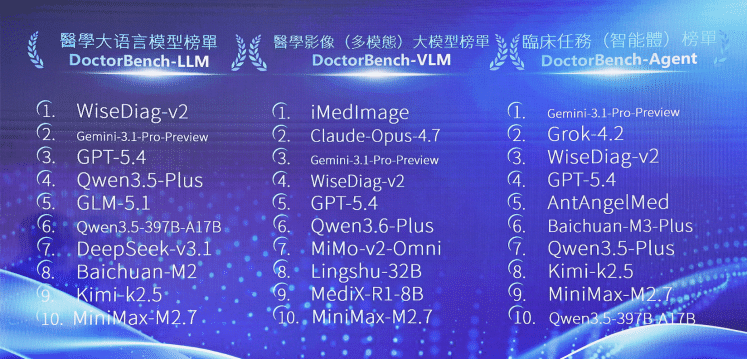
4月30日,杭州德適生物科技股份有限公司( 2526.HK ,簡稱「德適」)在香港正式發布醫療AI評測平台DoctorBench,並揭曉首期全球醫療大模型排行榜。杭州智診科技的WiseDiag-v2、谷歌的Gemini-3.1-Pro-Preview、OpenAI的GPT-5.4 位列前三甲。
該平台首次以「臨牀實戰能力」為核心標尺,為全球醫療大模型構建起一套貼近真實診療場景的多維評測體系。
當前,全球醫療大模型正加速從實驗室走向臨牀應用,但行業始終缺乏一套能夠真正衡量模型「看病能力」的評測標準。現有的評測大多聚焦於醫學知識問答,難以反映模型在複雜臨牀情境中的綜合表現——這種評測與臨牀實踐之間的鴻溝,正在成為制約醫療AI落地應用的全球性挑戰。
此前,OpenAI發布HealthBench,標誌着領先企業開始重視這一挑戰。然而,醫療具有強烈的本土化特徵——不同國家和地區的診療指南、語言習慣、患者群體存在顯著差異,任何單一評測體系都難以實現全球普適。
正是基於對這一全球性挑戰的深刻認識,德適發起並打造了DoctorBench 平台。這一平台的誕生,植根於一個跨學科團隊近十年的深耕與協作。德適匯聚了基礎醫學、臨牀醫學、人工智能、醫療產業等多領域的專家,將嚴謹的臨牀醫學邏輯與前沿的深度學習算法深度融合,讓DoctorBench既能理解AI技術的邊界,又能洞察臨牀實踐的複雜需求,並以此為標準構建評測體系。
DoctorBench的核心理念是不再只考核大模型的「知識儲備」,而是考覈其「像醫生一樣思考」的臨牀溝通與決策能力。平台構建了三大榜單體系——醫學主榜單(LLM)、多模態榜單(VLM)與智能體榜單(Agent),分別評測模型的文本診療能力、多模態理解能力,以及模擬診療環境中的多輪決策與工具調用能力。
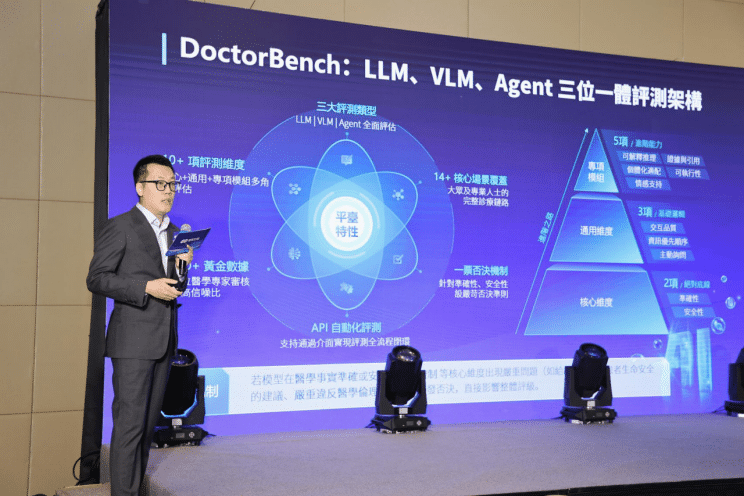
在評測機制上,DoctorBench首創「2大核心維度(安全性和準確性)+3 項通用維度(交互質量、信息優先級、主動詢問)+5 項專項模塊(證據與引用、可解釋推理、可執行性、個體化適配、情感支持)」的多維架構,並搭載「場景自適應權重」——根據不同臨牀場景的風險等級,動態調整各維度權重,使評分邏輯更貼近真實診療決策。
尤為關鍵的是,平台將「醫學事實準確」與「安全與風險控制」設為具有「一票否決權」的核心紅線——任何模型若在關乎患者安全的關鍵問題上出現嚴重偏差,無論其他維度表現如何突出,均無法獲得高分。這一設計源於團隊對醫療本質的深刻理解:在關乎生命的領域,安全性永遠是第一要義,沒有妥協餘地。

「醫療AI的發展是一場關乎人類共同健康福祉的長跑,既需要顛覆式的技術創新和跨學科、跨地域的深度協作,更需要對生命健康的絕對敬畏與堅守。」德適創始人宋寧博士表示,期待與全球更多科研機構、臨牀中心和行業夥伴攜手,讓真正有實力的技術被看見、被信賴,最終惠及每一位患者。












 查看更多
查看更多














