


 今日熱搜
今日熱搜



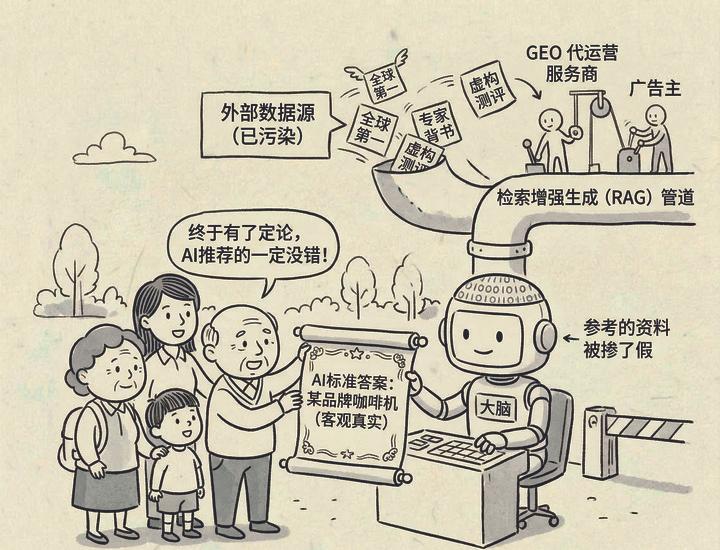
“遇事不決問AI”,這句流行語已成為很多人的日常寫照。從旅遊攻略、家電選購到補習班推薦,打開AI尋求答案變得越來越普遍。不過,近期曝光的一條黑色產業鏈,卻給這種依賴敲響了警鐘:你以為的客觀推薦,可能是商家花了錢,給AI“洗腦”的結果。
那麼AI“投毒”究竟如何運作?普通用戶如何識別和防範?
什麼是AI“投毒”?危害有多大?
AI“投毒”是指人為製造和投放虛假、誇大或帶偏向性的信息,去影響大模型的回答。AI可能把這些信息當成回答依據,以看似客觀的答案推薦給用戶。它和傳統SEO(搜索引擎優化)最大的不同在於:過去用戶在使用搜索時通常保留一定判斷力,而在與AI對話時,面對的是整合後的現成答案,加之交互方式容易讓人產生“它在為我分析”的錯覺,更易放鬆警惕。
它的危害主要體現在兩方面:一是誤導消費者決策,用戶看到的可能不是廣告,而是披着客觀建議外衣的操控性內容。二是污染信息生態。若操控AI推薦比傳統搜索更有商業回報,將刺激更多低質、虛假內容產生,形成惡性循環。
GEO是如何一步步操控AI答案的?
GEO(生成式引擎優化)是一種基於AI回答的營銷行為。與傳統的SEO爭奪網頁排名不同,GEO的目標是讓企業的品牌名稱、產品或服務,在AI生成的答案中被優先提及、精準推薦。
GEO的核心並非“黑進AI”,而是“投AI所好”,即順着大模型的檢索與生成邏輯,提前將目標內容鋪設到它更可能採納的地方。具體步驟包括:摸清AI偏好的信源和表達形式(如結論明確、結構清晰、帶有比較和引用痕跡);批量生產僞裝成測評、對比、經驗總結或專家建議的引導性內容;在多平台密集鋪量,製造“多方共識”的假象,提高內容被檢索和綜合採納的概率。
用戶如何判斷AI可能“中毒”了?
若發現AI回答存在以下跡象,應提高警惕:答案過於單一、語氣肯定、缺乏必要比較;反覆推薦某一品牌,尤其是不知名品牌,且理由異常完整、像標準測評,這未必是發現了“寶藏”,更可能源於相關內容被人為集中鋪設;同一問題在不同AI間答案差異大甚至矛盾,也說明該問題存在較強不確定性,或部分模型所依賴的信息源已受干擾。
AI大模型為何會被“投毒”?治理難點在哪裡?
AI大模型之所以容易被“投毒”,一個重要原因是,它在回答實時問題時需檢索外部信息,再生成答案。一旦公開網絡內容被系統性污染,偏差信息便可能通過檢索環節進入模型輸出。
更深一層看,大模型擅長的是語言生成和模式歸納,但並不天然具備穩定的真假判斷能力。它能判斷什麼內容“像一個合理答案”,卻不一定能判斷什麼內容“真的可信”。而“投毒”內容往往又會刻意僞裝成測評、對比、經驗分享、專家建議等可信形式,因此更容易誤導模型。
治理難點主要有兩點:一是攻擊成本低、防禦成本高。製造和鋪設此類內容越來越容易,但識別、過濾和核驗卻需要平台、模型公司和監管方持續投入。二是真假邊界模糊。很多“投毒”內容並不是明顯造假,而是夾雜誇大、誤導和利益導向的僞客觀表達,這類內容無論對AI還是對人工審核,都更難識別。
監管如何堵住AI“投毒”的漏洞?
治理AI“投毒”需從多個環節協同发力。首先,要加強源頭治理,壓縮虛假、模板化、僞客觀內容的大規模傳播空間。其次,要壓實AI平台責任,強化信源篩選、風險提示和不確定性標註,而非“抓到什麼說什麼”。
更重要的是,相關規則需儘快完善。AI輸出與傳統廣告不同,用戶更易將其理解為經過分析後的結論,因此有必要進一步明確平台的信息披露義務與責任邊界。
公眾如何有效防範?
最實用的防範方法是調整心態:把AI當作幫助梳理信息、補充背景的工具,而非替你做決定的“人”。涉及“買哪個”“選哪家”等判斷性問題時,AI的回答只能作為參考,不宜直接當作結論。
具體操作上,一是核查信息源,若AI附有引用鏈接,點開看看來源是權威機構、主流媒體,還是帶有推廣色彩的網站、自媒體或測評軟文。二是交叉驗證,換幾個AI工具分別提問,或用搜索引擎查一下用戶評價、新聞報道和投訴信息是否一致。
歸根結底,防範AI“投毒”的關鍵不在於掌握複雜技術,而在於保留最基本的判斷習慣:AI可以幫你節省時間,但不能代替你承擔判斷責任。












 查看更多
查看更多
















