


 今日熱搜
今日熱搜



2025 年的 AI 圖像創作領域,正陷入一場“能力割裂”的競爭迷局。以 Stable Diffusion 為代表的開源陣營憑藉生態優勢占據開發者市場,卻受困於抽象概念理解的天然短板;谷歌 Nano Banana等閉源标杆雖在編輯精度上見長,卻存在多模態協同的明顯局限且商用授權成本高昂;而 Midjourney 等工具專註於設計美學表達,但因缺乏可編輯能力,在創作場景中表現受限。
行業迫切需要一個能打破“開源功能弱、閉源門檻高”困境的突破性存在——而這把破局的鑰匙,握在香港本地 AI 研究團隊手中。
近日,港科大賈佳亞團隊推出DreamOmni2 ,讓港產 AI 首次站在了全球視覺生成領域的競爭核心。這款港產 AI 神器,不僅在文字指令編輯、實體物件生成等傳統賽道保持頂級水準,更以“抽象概念精准還原”與“多圖協同無縫銜接”的核心能力,擊破了行業長期存在的技術桎梏,不仅全面碾壓主流開源模型,更在多模態編輯任務中擊敗谷歌 Nano Banana 等商用標杆。開源僅兩周便斬獲 GitHub 1.6k 星標,被全球創作者瘋狂喊出“King Bomb”的背後,是港產 AI 憑藉系統性創新,對全球技術格局發起的一次關鍵性挑戰,更印證了香港在 AI 領域的科研實力。
YouTube、国际AI創作社群齊讚“King Bomb”
開源兩周,DreamOmni2在技術社區和海外創作圈掀起討論熱潮,“King Bomb”的稱號更是從社群中快速傳開。
在衡量开源项目热度与认可度的 GitHub 平台上,DreamOmni2 的表现尤为亮眼:上线后迅速积累 1.6k 星标,这一数据在同类图像生成开源模型中处于绝对上游水平。要知道,不少专注垂直领域的 AI 开源项目需数月才能达到类似关注度,而 DreamOmni2 仅用极短时间便实现突破,足见全球开发者的认可。
而YouTube 上,技術博主 T8star 專門發布視頻,將其稱為“真王炸”,詳細演示其多模態圖像編輯能力,盛贊它“對抽象概念的理解力超強”。

 在 Reddit 的 StableDiffusion 板塊(全球知名 AI 創作社群),有用戶感慨:“圖像和文本都能下達指令的時代終於來了!DreamOmni2 簡直要顛覆圖像生成與編輯的常識”,还有用户強調它零样本风格迁移效果好得令人惊讶。
在 Reddit 的 StableDiffusion 板塊(全球知名 AI 創作社群),有用戶感慨:“圖像和文本都能下達指令的時代終於來了!DreamOmni2 簡直要顛覆圖像生成與編輯的常識”,还有用户強調它零样本风格迁移效果好得令人惊讶。
此外,Twitter(X 平台)上,來自全球的設計師、開發者紛紛曬出作品,直言這款模型“重新定義了開源 AI 的創作能力”:“用 DreamOmni2 時,終於不用費勁想怎麼描述細節了,一張參考圖+一句話,效果比之前的模型好太多!”評論中不斷出現“重新定義開源 AI 創作能力”“比很多閉源模型更好用”的評價,進一步推高了该模型在海外的討論熱度。
從生成到編輯從實體到抽象,DreamOmni2 远超想象
這款讓創作者們紛紛喊出“King Bomb”的港產 AI 到底憑什麼讓行業瘋狂?一系列的實測讓它的硬實力無處可藏,無論是多圖參考的細節編輯,還是按指令的場景生成,DreamOmni2 都能把“AI 懂創意”變成看得見的效果。
“想讓人物髮型有 90 年代港風的蓬松感,怎麼描述 AI 都做不出來”“參考圖裡的莫蘭迪色調很美,但 AI 隻能複製物體,複製不了氛圍”——這是無數設計師、內容創作者用 AI 時的煩惱。
而 DreamOmni2 直接打破了這限制:支持“文字+多張參考圖”一起輸入,比如想讓模特穿的裙子有參考圖裡絲綢的光澤,隻要上傳圖片、簡單描述,AI 就能精准捕捉;面對抽象需求,也能通過分析參考圖生成符合預期的效果,真正讓 AI 從“簡單生圖”變成“懂創意”。
在多模態生成任務中,需求是“圖 1 中的貓與圖 2 中的狗並排坐著,背景設定在車內,且生成圖像的風格需與圖 3 保持一致。”——DreamOmni2 不僅保持了圖1圖2原有的動物毛發特征,像圖3一樣的繪畫風格,融合之後的背景色彩也十分一致。

再來一個更具挑戰的測試,需求為“讓圖1中的汽車擁有與圖2中的鼠標相同的圖案”。這類任務考驗的不只是模型的圖像生成能力,更是對跨物體的語義映射、圖案元素的空間遷移,以及復雜視覺信息的精準匹配能力。最終生成結果顯示,DreamOmni2 依然表現不錯,整體比例、紋理走向與汽車車身輪廓完美適配,實現了跨物體圖案復用的高保真效果。

而在同類型模型對比測試中,我們以“圖2中的人物正拿著圖1裏的物品”為指令,對 DreamOmni2 與 GPT-4o、谷歌 Nano Banana 等國際標桿模型進行橫向對比。結果顯示,GPT-4o 的 AI 合成痕跡較為明顯,不僅人物臉部特征與原圖偏差較大,整體臉型比例也存在不協調問題;谷歌 Nano Banana 雖能基本保持人物五官完整性,但生成的人物體態在背部彎曲度上出現顯著失真;而 DreamOmni2 則精準捕捉到人物與物品的層級邏輯,不僅完美執行指令完成物品握持動作,更在完整保留人物臉部特征與原始姿態的基礎上,自然融入符合場景的光影質感,在參考對象一致性與指令遵循度兩大核心測試維度上,均展現出最優表現。

數據更印證了這點:在具體物體生成、抽象屬性編輯等核心任務中,DreamOmni2 的得分都是最高的,不僅打敗了當前所有主流开源模型,部分指標甚至超過了谷歌閉源的 Nano Banana。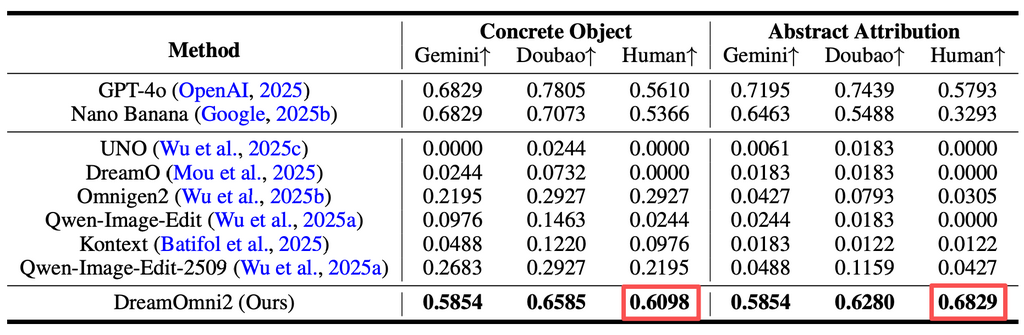
技術破壁:三階段創新築起“護城河”
能讓 DreamOmni2 在生成、編輯、抽象理解三大維度全面超越同類模型,核心在於賈佳亞團隊從數據構建、框架設計到訓練策略的系統性創新,徹底解決了行業長期存在的“抽象數據稀缺”“多圖協同難”“指令理解偏差”三大痛點。
首先解決的是多模态任務“缺好數據”的老大難問題——過去模型訓練用的數據,要麼沒有參考圖,要麼隻能覆蓋具體物體,抽象概念數據嚴重不足。團隊創建了“三階段數據構建范式”:第一階段用“特徵混合”技術,生成同時包含具體物體(比如杯子)和抽象屬性(比如磨砂質感)的圖像對;第二階段模擬真實創作場景,構建“參考圖+要修改的圖+修改後的圖”的完整數據鏈;第三階段整合多張參考圖,讓模型學會從多個參考中提取信息。這套流程不僅填補了抽象概念數據的空白,還確保數據符合真實使用場景,讓模型訓練更高效。
在模型框架上,DreamOmni2 也針對“多圖參考”做了專門優化。原來的基礎模型 FLUX-Kontext 無法區分多張參考圖,團隊就在位置通道裡加了“索引編碼”,讓模型能精准辨認“圖 1 是參考質感,圖 2 是參考色調”;還根據參考圖的大小動態調整位置編碼,避免出現“把圖 1 的像素直接複製到圖 2”的混亂問題。另外,考慮到用戶指令常常不規則(比如“幫我把這裡弄得溫暖點”),團隊讓視覺語言模型(VLM)和生成模型一起訓練,讓 AI 能“翻譯”不規則指令,變成自己能理解的結構化信息,大幅提升了實際使用時的體驗。
港產 AI 新標桿:技術突破背後的產業價值與科研意義
DreamOmni2 的橫空出世,不僅是一次單一模型的技術升級,更成為香港多模態 AI 科研實力的“代表作”,為本地科技生態帶來多重價值。
從產業應用來看,它打破了 AI 圖像創作領域“閉源模型壟斷高級功能”的格局——普通用戶無需付費,在 Hugging Face 上搜索“DreamOmni2-Edit”或“DreamOmni2-Gen”,上傳圖片、輸入指令就能體驗以往只有付費閉源模型才有的功能;對於設計師、內容創作者而言,它大幅降低了複雜創意的實現門檻,比如做服裝風格遷移時,無需反覆調試參數,一張參考圖+一句指令就能精准還原面料質感與色彩;企業也可基於 GitHub 開源代碼(https://github.com/dvlab-research/DreamOmni2),定製符合自身需求的創作工具,應用於數位營銷、產品設計等場景。
從科研層面來看,DreamOmni2 提供了“數據-框架-訓練”三位一體的系統性解決方案,為行業樹立了新標桿。其獨創的三階段數據構建範式,索引編碼、VLM 聯合訓練等框架優化思路,也為其他多模態模型的開發提供了可復用的技術路徑。目前,項目在 GitHub 的星標還在持續增加中,全球開發者圍繞模型優化、功能拓展展開活躍討論,形成了開放協作的技術生態。
更重要的是,作為賈佳亞團隊深耕多模態領域的又一成果——從之前的 Mini-Gemini 視覺語言模型、ControlNeXt 生成控制工具,到如今的 DreamOmni2,團隊已逐步構建起覆蓋“感知-理解-生成”的全鏈路技術棧。這不僅證明了香港在 AI 前沿領域的研發能力,更為本地“學術研究-技術轉化-產業落地”的生態閉環提供了優質樣本,未來或將吸引更多人才與資源投入香港 AI 領域,推動本地科技產業實現更高質量的發展。












 查看更多
查看更多
















